你有没有过这样的经历:本来只是想打开 X/Twitter 看一眼行业动态,结果十几分钟后,你已经点进了一个陌生账号的评论区,又顺手看了几个争议帖、热点帖、反驳帖。等你回过神来,原本要做的事情已经被打断,脑子里还多了一堆和自己目标无关的信息。
这不是简单的“自控力差”。背后真正起作用的,是一个为实时筛选、排序和预测用户行为而设计的推荐系统。
理解推荐系统,不是为了和算法对抗,也不是为了研究如何“骗过算法”,而是为了知道:哪些行为会让系统继续喂给你更多同类内容,哪些设置和使用习惯能帮你重新拿回注意力。
本文分两部分:第一,X/Twitter 的“为你推荐”流大概是怎么工作的;第二,普通用户如果只想保持专注,可以怎样改造自己的使用方式。
一、推荐流不是时间线,而是一套实时排序系统
很多人还会下意识把 Twitter 当成一个“时间线产品”:我关注了谁,就按时间顺序看到谁发的内容。但今天的 X/Twitter,尤其是 For You / 为你推荐,已经不只是关注列表的自然展开,而是一个实时推荐系统。
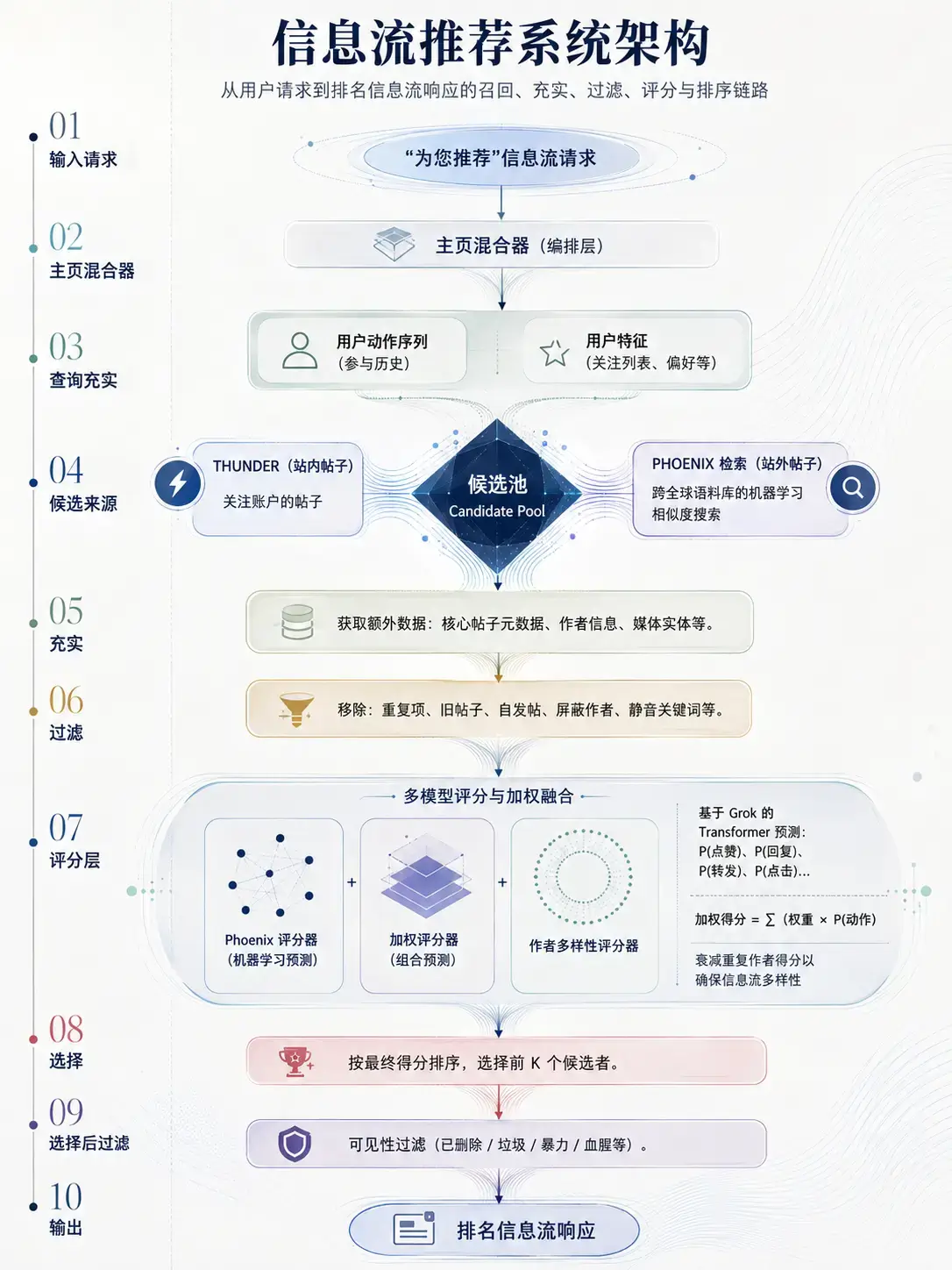
X 官方工程博客在 2023 年介绍过,推荐系统的任务,是从每天大量发布的帖子中筛出少量最可能出现在用户 For You 时间线里的内容;官方也把这个流程概括为三个主要阶段:候选内容召回、机器学习排序、启发式规则与过滤。
这意味着,当你打开 For You 时,系统并不是简单地问:
“你关注的人最近发了什么?”
它真正要回答的问题更像是:
“在此刻,对这个用户来说,哪些帖子最可能引发点击、停留、点赞、回复、转发或其他互动,并且符合平台展示规则?”
所以推荐流的本质不是“内容列表”,而是一个不断学习你行为的排序漏斗。
二、从打开首页到看到内容,中间发生了什么?
可以把 X/Twitter 推荐流想象成一条生产线:先理解用户,再召回候选内容,然后补全信息、过滤、打分、重排,最后输出到你的屏幕上。
1. 你发起一次“为我推荐”的请求
当你打开首页或刷新 For You 时,系统收到一个请求。这个请求里最重要的不是“时间”,而是“用户上下文”。
也就是说,系统会关心你是谁、你关注谁、你最近看了什么、你曾经喜欢什么、你经常忽略什么、你和哪些账号有互动、你对哪些主题有明显兴趣。
这一步决定了后面推荐系统要围绕什么样的用户画像来工作。
2. Home Mixer:推荐流的总编排层
在公开资料中,Home Mixer 是构建和服务 Home Timeline 的核心服务之一。你可以把 Home Mixer 理解成一个“总调度器”。它不一定亲自判断每条帖子好不好,而是负责把不同候选源、用户信号、排序模型、过滤器、广告模块、关注推荐模块等组件串起来。
这就像一家新闻编辑部的主编系统:不同记者提供线索,不同审核环节检查风险,不同编辑规则控制版面,最终才形成你看到的信息流。
3. 查询充实:系统先补全“你是谁”
这一步对应的是用户动作序列和用户特征。
用户动作序列包括你最近的点赞、回复、转发、点击、停留、展开图片、观看视频、访问主页、搜索、点“不感兴趣”、静音、拉黑等行为。用户特征则包括关注列表、兴趣主题、语言偏好、历史曝光记录、社交图谱关系等。
这一步非常关键,因为推荐系统并不是只看“帖子本身火不火”,而是要判断:
“这条帖子对于你这个人,是否可能有吸引力?”
同一条帖子,对 A 用户可能是高相关内容,对 B 用户可能完全无关。
4. 候选召回:从海量帖子里先捞出一批可能相关的内容
推荐系统不可能每次都把全站所有帖子逐条打分,成本太高。所以它会先做“候选召回”:从多个来源里快速找出一批可能值得推荐的帖子。
通常可以粗略分成两类。
第一类是 In-Network / 关注网络内容,也就是你关注的人发的帖子。它解决的是:你关注的人里,哪些近期内容值得进入候选池?
第二类是 Out-of-Network / 非关注网络内容,也就是你没有关注的人发的帖子。系统会根据你关注的人互动过什么、与你兴趣相似的人喜欢什么、内容语义是否相近、社区或话题嵌入是否相关等因素,寻找你可能感兴趣但尚未关注的内容。
这就是为什么你会在 For You 里看到大量陌生账号。不是因为它们“随机出现”,而是系统认为这些内容和你的行为、兴趣、社交图谱或相似用户群体有关。
图里把这两路分别写成 THUNDER 和 PHOENIX。这里要注意一个误解:图里的“站外帖子”更准确地说应理解为“非关注网络帖子”,不是外部网站内容。它仍然是 X/Twitter 平台内的帖子,只是来自你尚未关注的作者。
5. 候选池:先合并,再筛选
关注网络和非关注网络各自召回一批帖子之后,会进入一个候选池。此时这些帖子还不是最终结果,只是“值得进一步处理”的候选。
推荐系统前半段更重视召回率:先尽可能找出一批潜在相关内容,再交给后续模型和规则进行精筛。这个过程像漏斗:前面多、粗、快,后面少、精、慢。
所以,你最终看到的几十条内容,背后其实可能经历了从海量内容到候选池、再到最终展示的多轮筛选。
6. 候选充实:给每条帖子补全上下文
一条帖子进入候选池时,系统拿到的可能只是帖子 ID 和少量基础信息。为了判断它是否适合展示,系统还需要补全更多特征。
例如:帖子发布时间、语言、是否带图片或视频、是否包含链接、作者账号状态、作者与你的关系、互动数量、媒体安全信号、回复上下文、是否曾经展示给你、是否命中某些限制规则等。
这一步可以理解成:系统不只是看“这条帖子写了什么”,还看“谁写的、什么时候写的、谁互动了、你和作者有什么关系、它是否安全、你是否已经看过”。
7. 过滤:很多内容不是排名低,而是根本不能进排名
过滤层非常重要。很多内容不是因为“分数不够高”才没出现在你面前,而是在打分或最终展示前就被过滤掉了。
常见过滤包括:重复内容、已经看过的内容、太旧的内容、你自己的帖子、你拉黑或静音作者的内容、命中静音关键词的内容、NSFW 设置不允许的内容、不可见内容、删除内容、垃圾内容等。
所以,当你看不到某些内容时,可能有三种情况:它没有被召回;它被召回了,但过滤掉了;它被打分了,但排序靠后。
普通用户往往只关注第三种,但真实推荐系统里,前两种同样重要。
8. 评分:系统预测的不是一个动作,而是一组行为概率
推荐系统最核心的一步是评分。
很多人以为算法只是在预测“你会不会点赞”。其实更准确地说,它会预测多个行为概率:你会不会点赞、回复、转发、点击、停留、看视频、点进主页、关注作者,甚至也可能预测你是否会给出负反馈。
可以把最终分数简化理解成这样:
最终分数 =
点赞权重 × P(点赞)
+ 回复权重 × P(回复)
+ 转发权重 × P(转发)
+ 点击权重 × P(点击)
+ 停留权重 × P(停留)
+ 关注作者权重 × P(关注作者)
- 负反馈权重 × P(不感兴趣 / 静音 / 拉黑 / 举报)
+ 新鲜度、质量、多样性、关系强度等调整
真实系统当然更复杂,但这个简化公式足够说明一个重点:
你对内容的每一次反应,都会成为系统理解你的一部分。
你喜欢一条内容,是信号。你点开一条内容,是信号。你停留很久,是信号。你进入评论区围观,也是信号。你因为愤怒反驳,也可能被系统理解成“这类内容能让你产生强互动”。
这就是为什么“我讨厌这种内容,但总是刷到”并不矛盾。因为推荐系统不一定能准确理解你的价值判断,它更容易捕捉你的行为反应。
9. 多样性和重排:防止同一类内容刷屏
如果只按预测分数排序,信息流很容易变得单调。比如,一个作者与你高度相关,模型可能连续给他的帖子高分;或者某个热点非常吸引你,系统可能不断推同类争议内容。
因此,推荐流通常还会做重排和多样性控制。
这一步的目标是让信息流看起来“丰富”“自然”“有节奏”。但对普通用户来说,这也意味着:你看到的并不是一个纯粹的分数榜,而是模型评分、产品规则、安全规则、多样性规则共同作用的结果。
10. 混排与输出:最终变成你看到的信息流
当系统选出一批帖子后,还会混入其他内容,例如广告、关注推荐、提示模块等。
最终,你看到的是一条被多轮加工过的信息流。
它不是“全站最热”。也不是“你关注的人按时间排序”。更不是“客观重要内容榜”。
它是系统根据你的历史行为、当前上下文、候选内容、互动概率、安全规则、产品目标和多样性约束共同生成的一组结果。
三、为什么推荐流特别容易让人分心?
理解上面的机制之后,就能看出推荐流为什么容易让人失去专注。
它不是一次性给你一份固定列表,而是不断根据你的行为调整下一批内容。你点什么,它就学什么;你停在哪里,它就记什么;你和什么内容纠缠,它就继续测试你是否还会纠缠。
这会造成几个问题。
第一,推荐流没有天然终点。你不是读完一本书、看完一篇文章,而是在一个持续生成的内容池里滑动。
第二,推荐流很擅长捕捉“弱兴趣”。你并不一定真的喜欢某个话题,但只要你停留、点开、看评论,它就可能继续给你更多类似内容。
第三,负面情绪也会变成互动。愤怒、焦虑、比较、反驳欲、围观欲,都可能让你产生点击和停留。
第四,推荐流会把“信息”和“刺激”混在一起。你打开 X 是为了看行业信息,但系统可能同时给你热点争吵、成功学截图、财富焦虑、政治对骂、娱乐八卦和各种短观点。它们未必有用,但很容易抓住注意力。
所以,保持专注的关键,不是要求自己“刷的时候更自律”,而是要改变入口、边界和互动方式。
四、如果只想保持专注,你可以怎么做?
1. 少进 For You,多用 Following 和 Lists
如果你想减少算法推荐对你的干扰,第一步就是少进 For You。
更好的做法是使用 Lists。你可以建立几个非常窄的列表,例如:
AI 产品
行业研究
高质量新闻源
朋友动态
客户与合作方
长期学习账号
然后把使用路径改成:
打开 X → 进入指定列表 → 看 10 分钟 → 退出
而不是:
打开 X → For You → 热点 → 评论区 → 陌生账号 → 相似推荐 → 忘记自己为什么打开
这一步的本质是:把 X 从“无限推荐流”改造成“白名单信息源”。
2. 建一个真正属于自己的“白名单信息流”
你不需要关注几千个账号,也不需要让推荐系统替你决定一切。
可以自己维护一个 30 到 100 人以内的高质量列表。列表里的账号应该满足一个标准:
看完之后,我更清楚自己下一步要做什么,而不是更焦虑、更愤怒、更想继续刷。
可以留下的账号,通常有这些特征:它们提供稳定、高密度、有上下文的信息;它们能帮你做判断,而不是只制造情绪;它们的内容与你当前的长期目标有关;它们让你产生行动,而不是只产生围观欲。
应该移出列表的账号,也很容易识别:总是让你焦虑;总是引发你比较;总是让你想吵架;总是把你带进评论区;总是让你看完以后脑子很乱。
白名单信息流的目的不是信息更少,而是信息更可控。
3. 大量使用静音词、静音账号和屏蔽
不要指望自己每次都能忍住不看。真正有效的办法,是从源头减少诱因。
你可以静音这些类型的词:
热点事件关键词
娱乐八卦关键词
让你焦虑的职业比较词
容易引战的人名
某些政治争吵词
流量标题词
你总会忍不住点进去看的话题
如果某个账号经常污染你的注意力,但你暂时不想取关,可以先静音账号。
这里的原则很简单:
不要跟干扰源讲道理,直接减少它出现的机会。
4. 不要把“反驳”和“围观”喂给算法
很多人以为自己是在抵抗垃圾内容:我点进去,是为了看看它有多离谱;我回复,是为了纠正错误;我转发,是为了批评它。
但从推荐系统的角度看,你已经贡献了信号。
你停留了。你点开了。你回复了。你看了评论。你甚至可能访问了作者主页。
这些行为不一定会被理解为“喜欢”,但它们很可能被理解为“这类内容能让你产生反应”。
所以最好的策略不是“边骂边看”,而是冷处理:
不点开
不进评论区
不访问主页
不截图传播
不转发批评
直接不感兴趣 / 静音 / 屏蔽
保持专注时,最重要的不是赢得一场评论区争论,而是不让无关内容拿走你的工作记忆。
5. 每次打开 X 之前,先写下目的
推荐流最容易影响没有明确目标的人。
如果你打开 X 时只是想“随便看看”,系统就有很大的空间把你带向任何能引发反应的内容。相反,如果你打开前已经知道自己要做什么,你就不容易被带跑。
你可以给自己设定这种打开方式:
我现在打开 X,是为了查 3 条 AI 产品更新。
我现在打开 X,是为了看行业列表 10 分钟。
我现在打开 X,是为了发布一条内容,然后退出。
我现在打开 X,是为了看某个作者最近有没有更新。
没有目的,就不要打开。
这句话听起来简单,但非常有效。因为它把使用 X 从“被动接收”变成了“主动检索”。
6. 把“即时阅读”改成“保存后处理”
看到有价值的内容时,很多人会立刻点开、深读、看评论、看作者主页、看引用转发,然后被带到更多内容里。
更好的做法是建立一个“稍后处理”机制:
有用内容 → 收藏或复制到笔记
需要深读 → 放进稍后阅读
值得研究 → 每天固定时间统一处理
想回复 → 延迟 10 分钟再决定
想争论 → 默认不回复
即时阅读容易被链路带走。保存后处理则把信息从推荐流里“取出来”,放到你自己的系统里。
这一步很关键:你不是在 X 里完成思考,而是把材料带回自己的工作台。
7. 设置硬边界:时间、设备和场景
推荐流没有天然终点,所以你必须人为制造终点。
比较有效的边界包括:
每天只看 2 次,每次 10 分钟
只在电脑上看,不在手机上看
不在早上第一小时看
不在睡前一小时看
只看列表,不看 For You
看完必须产出一条笔记
其中最值得执行的是:
不要在早上第一小时刷 X。
早上的注意力最干净。如果一醒来就进入热点、争吵、新闻、比较和碎片观点,你当天的思维节奏很容易被外部信息设定。
你可以把 X 放在一天中的低风险时段,比如午饭后或下午固定 15 分钟。不要让它成为一天的开机画面。
五、一个 7 天专注改造方案
如果你想真正改变使用习惯,可以直接按下面的 7 天计划执行。
第 1 天:清理关注列表
取关 20 个让你长期焦虑、愤怒、比较、上头或分心的账号。
判断标准不是“这个账号有没有价值”,而是:
它是否服务于我现在的生活和工作目标?
很多内容并非完全没价值,只是对你当前阶段不重要。
第 2 天:建立一个高质量列表
创建一个名为“高质量输入”或“专注信息源”的列表,只放 30 个以内账号。
这个列表应该是你以后打开 X 的默认入口。
第 3 天:设置静音词
静音 30 个关键词,包括热点词、争吵词、人名、八卦词、焦虑词和你总是忍不住点进去的话题。
不要怕静音过度。你真正重要的信息,不会因为静音几个流量词就消失。
第 4 天:关闭通知
关闭 X 的非必要通知,尤其是推荐通知、热点通知、陌生人互动通知。
通知的危险在于,它会把你的注意力从当前任务中强行拉走。你不是主动打开 X,而是被 X 召回。
第 5 天:只用 Following 或 Lists
这一天不要主动刷 For You。只看 Following 或你自己创建的列表。
观察一下:你错过了什么?你减少了什么?你是否更容易退出?
第 6 天:每次打开前写下目的
打开 X 前,用一句话写下目的。完成后立刻退出。
例如:
目的:找 3 条 AI 产品更新。
目的:看完行业列表前 20 条。
目的:发完这条内容后退出。
如果你打开后忘了目的,就立刻关掉。
第 7 天:复盘你的注意力
最后一天问自己三个问题:
哪些内容让我更清楚?
哪些内容让我更焦虑?
哪些入口最容易让我失控?
然后继续取关、静音、调整列表。
专注不是一次性设置,而是持续维护自己的信息环境。
参考资料
- X Engineering:《Twitter’s Recommendation Algorithm》
https://blog.x.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm - GitHub:twitter/the-algorithm – Home Mixer README
https://github.com/twitter/the-algorithm/blob/main/home-mixer/README.md - GitHub:twitter/the-algorithm
https://github.com/twitter/the-algorithm - X Help Center:About your X timeline
https://help.x.com/en/using-x/x-timeline - X Help Center:How to use X Lists
https://help.x.com/en/using-x/x-lists - X Help Center:Advanced muting options on X
https://help.x.com/en/using-x/advanced-x-mute-options - X Help Center:How to mute accounts on X
https://help.x.com/en/using-x/x-mute