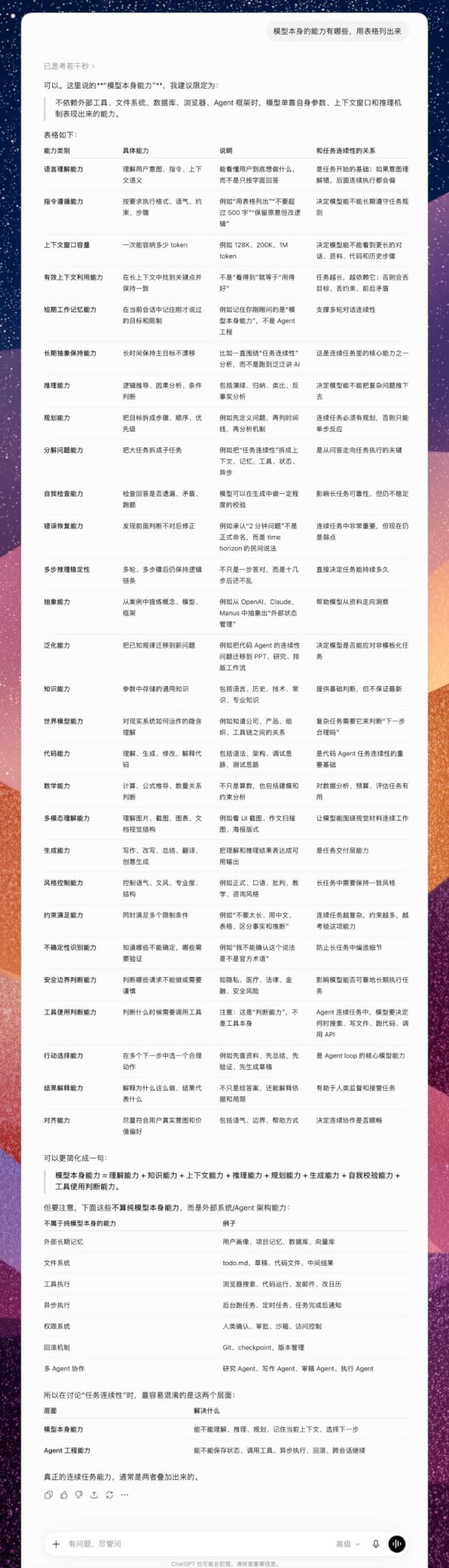
这里说的“模型本身能力”,建议限定为:
不依赖外部工具、文件系统、数据库、浏览器、Agent 框架时,模型单靠自身参数、上下文窗口和推理机制表现出来的能力。
模型本身能力表
| 能力类别 | 具体能力 | 说明 | 和任务连续性的关系 |
|---|---|---|---|
| 语言理解能力 | 理解用户意图、指令、上下文语义 | 能看懂用户到底想做什么,而不是只按字面回答 | 是任务开始的基础;如果意图理解错,后面连续执行都会偏 |
| 指令遵循能力 | 按要求执行格式、语气、约束、步骤 | 例如“用表格列出”“不要超过 500 字”“保留原意但改逻辑” | 决定模型能不能长期遵守任务规则 |
| 上下文窗口容量 | 一次能容纳多少 token | 例如 128K、200K、1M token | 决定模型能不能看到更长的对话、资料、代码和历史步骤 |
| 有效上下文利用能力 | 在长上下文中找到关键点并保持一致 | 不是“看得到”就等于“用得好” | 任务越长,越依赖它;否则会丢目标、丢约束、前后矛盾 |
| 短期工作记忆能力 | 在当前会话中记住刚才说过的目标和限制 | 例如记住刚刚问的是“模型本身能力”,不是 Agent 工程 | 支撑多轮对话连续性 |
| 长期抽象保持能力 | 长时间保持主目标不漂移 | 比如一直围绕“任务连续性”分析,而不是跑到泛泛讲 AI | 是连续任务里的核心能力之一 |
| 推理能力 | 逻辑推导、因果分析、条件判断 | 包括演绎、归纳、类比、反事实分析 | 决定模型能不能把复杂问题推下去 |
| 规划能力 | 把目标拆成步骤、顺序、优先级 | 例如先定义问题,再列时间线,再分析机制 | 连续任务必须有规划,否则只能单步反应 |
| 分解问题能力 | 把大任务拆成子任务 | 例如把“任务连续性”拆成上下文、记忆、工具、状态、异步 | 是从问答走向任务执行的关键 |
| 自我检查能力 | 检查回答是否遗漏、矛盾、跑题 | 模型可以在生成中做一定程度的校验 | 影响长任务可靠性,但仍不稳定 |
| 错误恢复能力 | 发现前面判断不对后修正 | 例如承认“2 分钟问题”不是正式命名,而是 time horizon 的民间说法 | 连续任务中非常重要,但现在仍是弱点 |
| 多步推理稳定性 | 多轮、多步骤后仍保持逻辑链条 | 不只是一步答对,而是十几步后还不乱 | 直接决定任务能持续多久 |
| 抽象能力 | 从案例中提炼概念、模型、框架 | 例如从 OpenAI、Claude、Manus 中抽象出“外部状态管理” | 帮助模型从资料走向洞察 |
| 泛化能力 | 把已知规律迁移到新问题 | 例如把代码 Agent 的连续性问题迁移到 PPT、研究、排版工作流 | 决定模型是否能应对非模板化任务 |
| 知识能力 | 参数中存储的通用知识 | 包括语言、历史、技术、常识、专业知识 | 提供基础判断,但不保证最新 |
| 世界模型能力 | 对现实系统如何运作的隐含理解 | 例如知道公司、产品、组织、工具链之间的关系 | 复杂任务需要它来判断“下一步合理吗” |
| 代码能力 | 理解、生成、修改、解释代码 | 包括语法、架构、调试思路、测试思路 | 是代码 Agent 任务连续性的重要基础 |
| 数学能力 | 计算、公式推导、数量关系判断 | 不只是算数,也包括建模和约束分析 | 对数据分析、预算、评估任务有用 |
| 多模态理解能力 | 理解图片、截图、图表、文档视觉结构 | 例如看 UI 截图、作文扫描图、海报版式 | 让模型能围绕视觉材料连续工作 |
| 生成能力 | 写作、改写、总结、翻译、创意生成 | 把理解和推理结果表达成可用输出 | 是任务交付层能力 |
| 风格控制能力 | 控制语气、文风、专业度、结构 | 例如正式、口语、批判、教学、咨询风格 | 长任务中需要保持一致风格 |
| 约束满足能力 | 同时满足多个限制条件 | 例如“不要太长、用中文、表格、区分事实和推断” | 连续任务越复杂,约束越多,越考验这项能力 |
| 不确定性识别能力 | 知道哪些不能确定,哪些需要验证 | 例如“我不能确认这个说法是不是官方术语” | 防止长任务中编造细节 |
| 安全边界判断能力 | 判断哪些请求不能做或需要谨慎 | 如隐私、医疗、法律、金融、安全风险 | 影响模型能否可靠地长期执行任务 |
| 工具使用判断能力 | 判断什么时候需要调用工具 | 注意:这是“判断能力”,不是工具本身 | Agent 连续任务中,模型要决定何时搜索、写文件、跑代码、调用 API |
| 行动选择能力 | 在多个下一步中选一个合理动作 | 例如先查资料、先总结、先验证、先生成草稿 | 是 Agent loop 的核心模型能力 |
| 结果解释能力 | 解释为什么这么做、结果代表什么 | 不只是给答案,还能解释依据和局限 | 有助于人类监督和接管任务 |
| 对齐能力 | 尽量符合用户真实意图和价值偏好 | 包括语气、边界、帮助方式 | 决定连续协作是否顺畅 |
简化理解
模型本身能力 = 理解能力 + 知识能力 + 上下文能力 + 推理能力 + 规划能力 + 生成能力 + 自我校验能力 + 工具使用判断能力。
不属于纯模型本身的能力
下面这些更偏外部系统或 Agent 架构能力:
| 不属于纯模型本身的能力 | 例子 |
|---|---|
| 外部长期记忆 | 用户画像、项目记忆、数据库、向量库 |
| 文件系统 | todo.md、草稿、代码文件、中间结果 |
| 工具执行 | 浏览器搜索、代码运行、发邮件、改日历 |
| 异步执行 | 后台跑任务、定时任务、任务完成后通知 |
| 权限系统 | 人类确认、审批、沙箱、访问控制 |
| 回滚机制 | Git、checkpoint、版本管理 |
| 多 Agent 协作 | 研究 Agent、写作 Agent、审稿 Agent、执行 Agent |
任务连续性的两层结构
| 层面 | 解决什么 |
|---|---|
| 模型本身能力 | 能不能理解、推理、规划、记住当前上下文、选择下一步 |
| Agent 工程能力 | 能不能保存状态、调用工具、异步执行、回滚、跨会话继续 |
真正的连续任务能力,通常是两者叠加出来的。